Creating Scalable Systems
Some food for thought. Consider the following:
- Prefer BASE over ACID transactions
- Prefer asynchronous over synchronous transactions
- Keeping state is expensive
- Considering database sharding (highscalability, codefutures, Pros and Cons) by data, by transaction or by customer but avoid premature optimisation
- Design the system for automated rollback
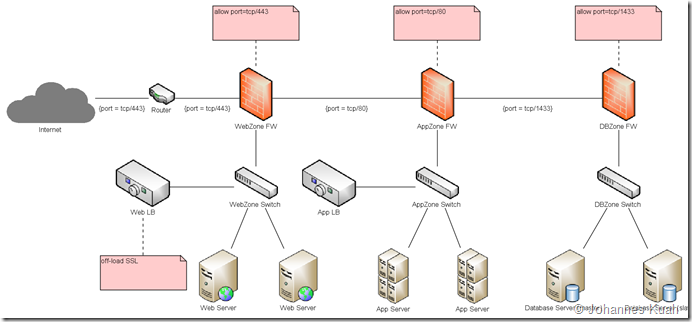
- Create isolative structures; share nothing; such that nothing crosses the swimlanes
- Design systems for failure
- Create idempotent services where possible
- Tables may need to be denormalised to optimise sharding (as well as to workaround cross-shard joins/ queries)
- Scale-out instead of scale-up
- Do away with replication where possible
- Vertical partitioning – sometimes known as functional or feature partitioning where data relating to certain entities are grouped together. Different functions or features are put onto different shards.
- Range-based partitioning – data for a certain function/ feature/ entity is sharded using ranges (such range may be based on year, location, etc.)
- Hash-based partitioning – data for a certain function/ feature/ entity is sharded using a hash function (modulo operation)
- Data needs to be rebalanced from time-to-time
- Joining data from multiple shards (cross-shard join) is expensive
- Referential integrity is now an issue since referential data may now be in a different database
- Sharding is relatively new; no body of knowledge and lack of support

Comments
Great post. Some remarks on Sharding - it is possible to do cross-shard joins, so no need for schema changes. Just use an off-the-shelf tool for that - like ScaleBase (disclosure - I work there). They give you transparent database sharding.